Lecture22 GPU Driven Geometry Pipeline - Nanite
Research Background
传统渲染管线
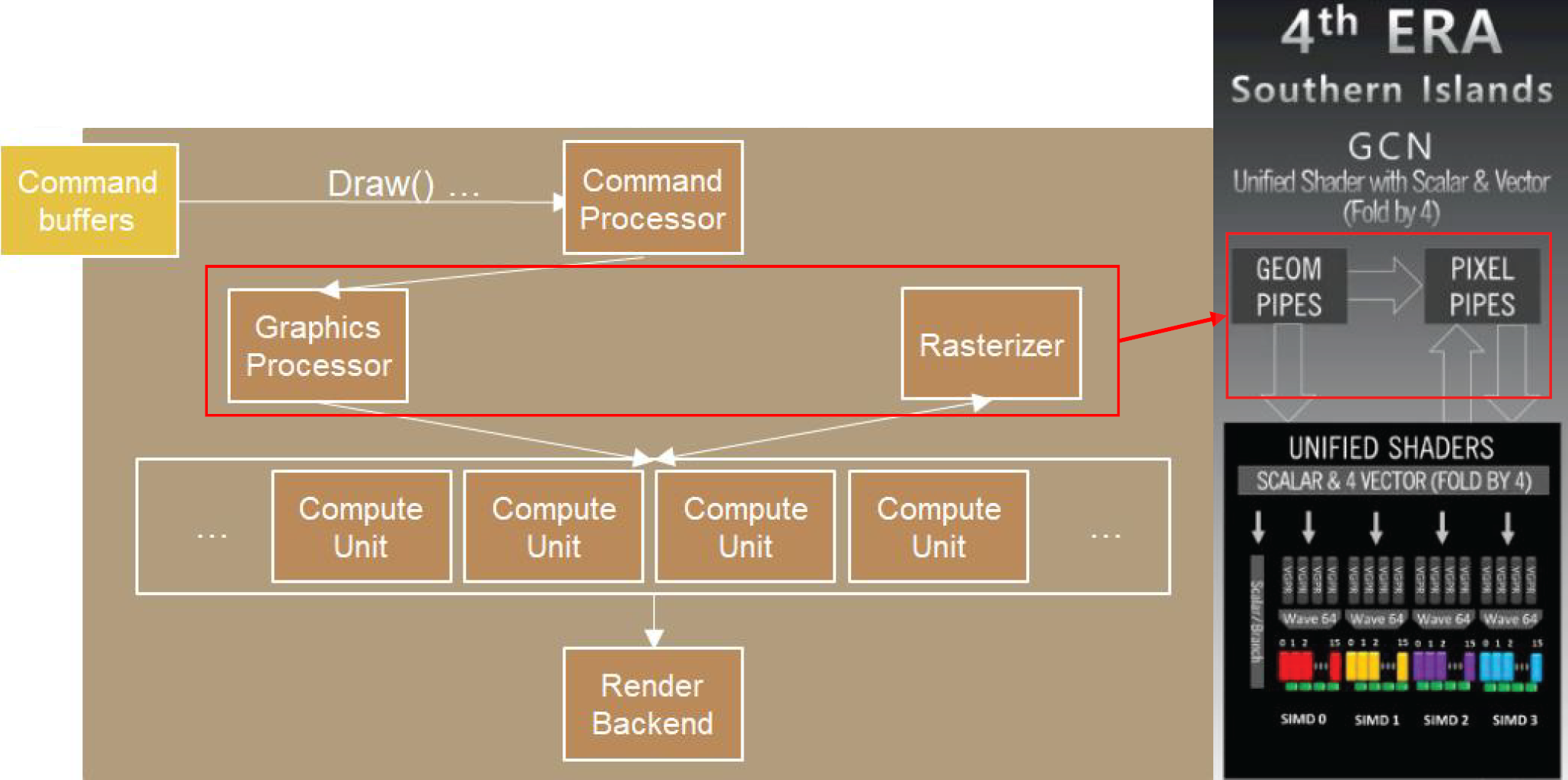
- CPU发起Draw Call,GPU准备State、进入漫长的Pipeline
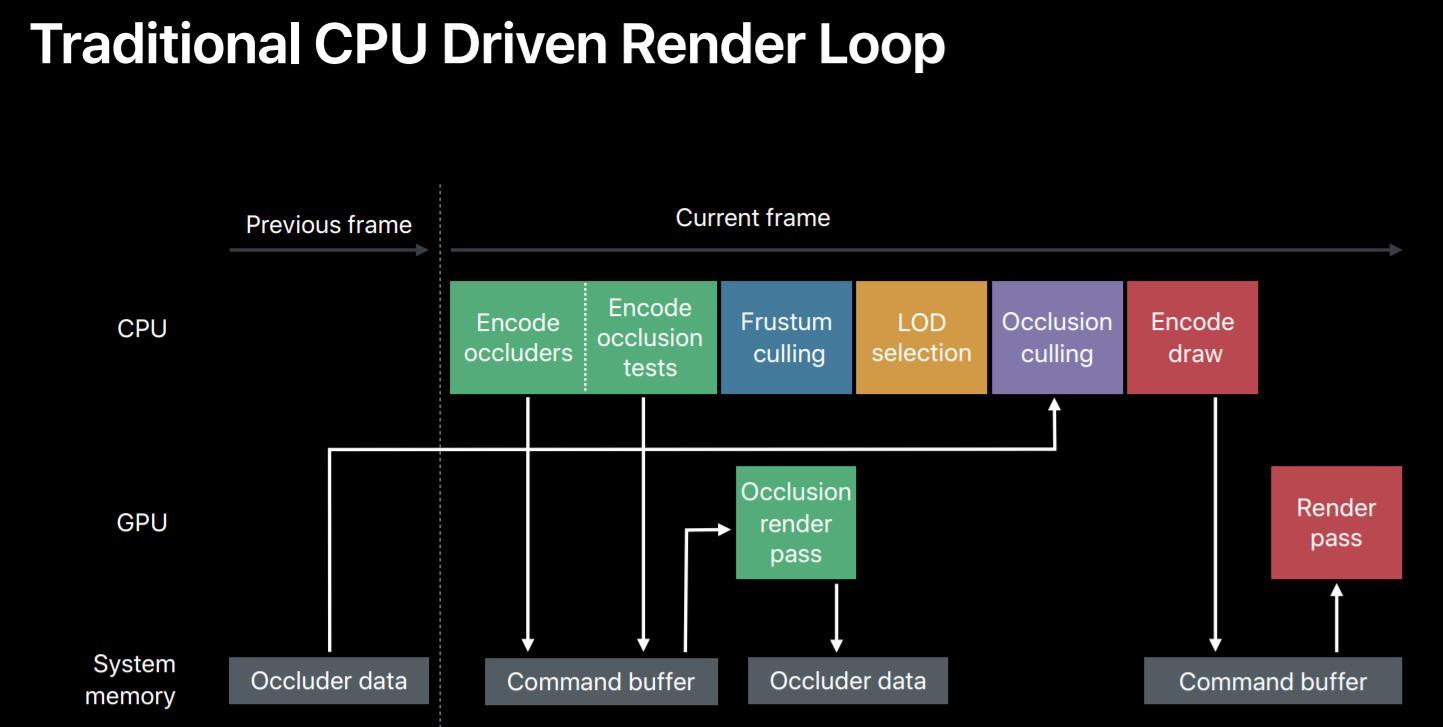
- CPU、GPU不同步
- 存在大量的算力浪费
- 现代游戏Draw Call越来越复杂,已经成为现代渲染管线瓶颈
- “曙光”:
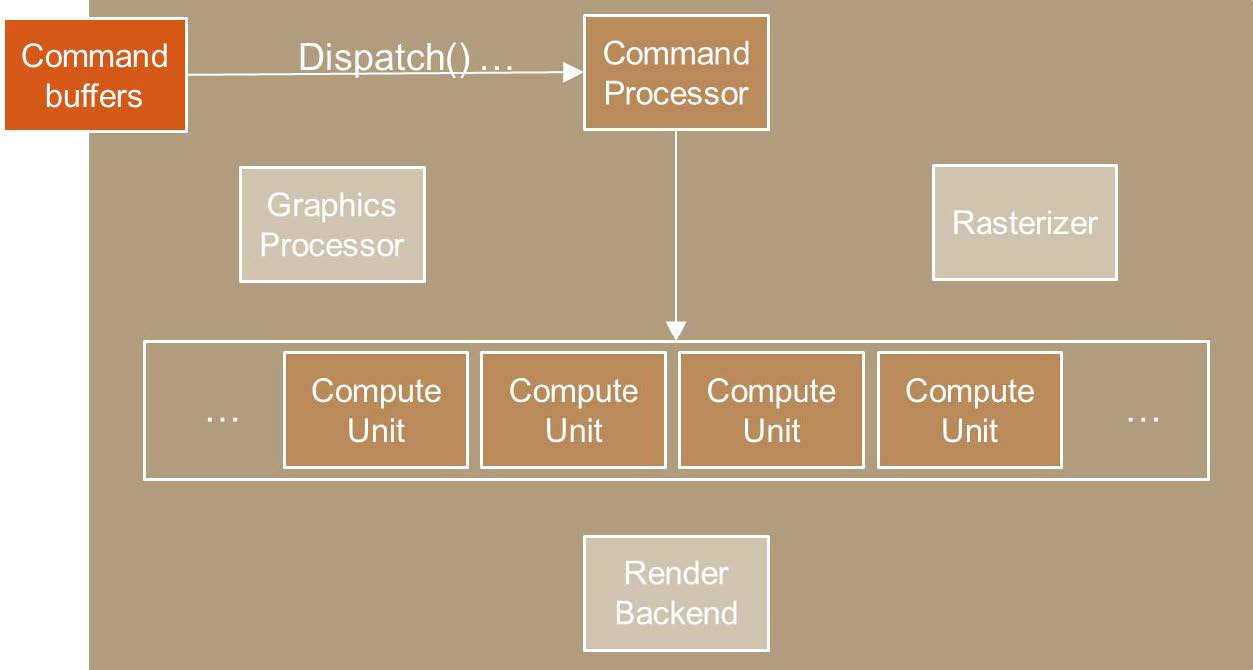
- Compute
Shader:不再需要在CPU、GPU之间来回传递数据,直接在GPU中执行通用计算
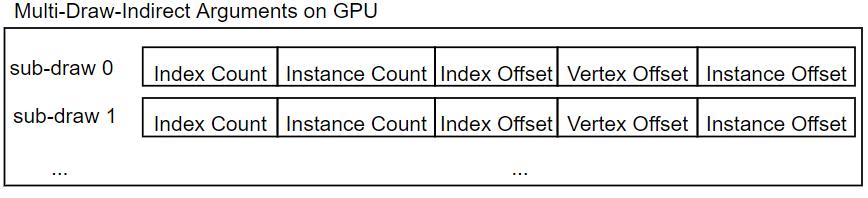
- Draw-Indirect Graphics API:一次Draw Call绘制多个Mesh
- Compute
Shader:不再需要在CPU、GPU之间来回传递数据,直接在GPU中执行通用计算
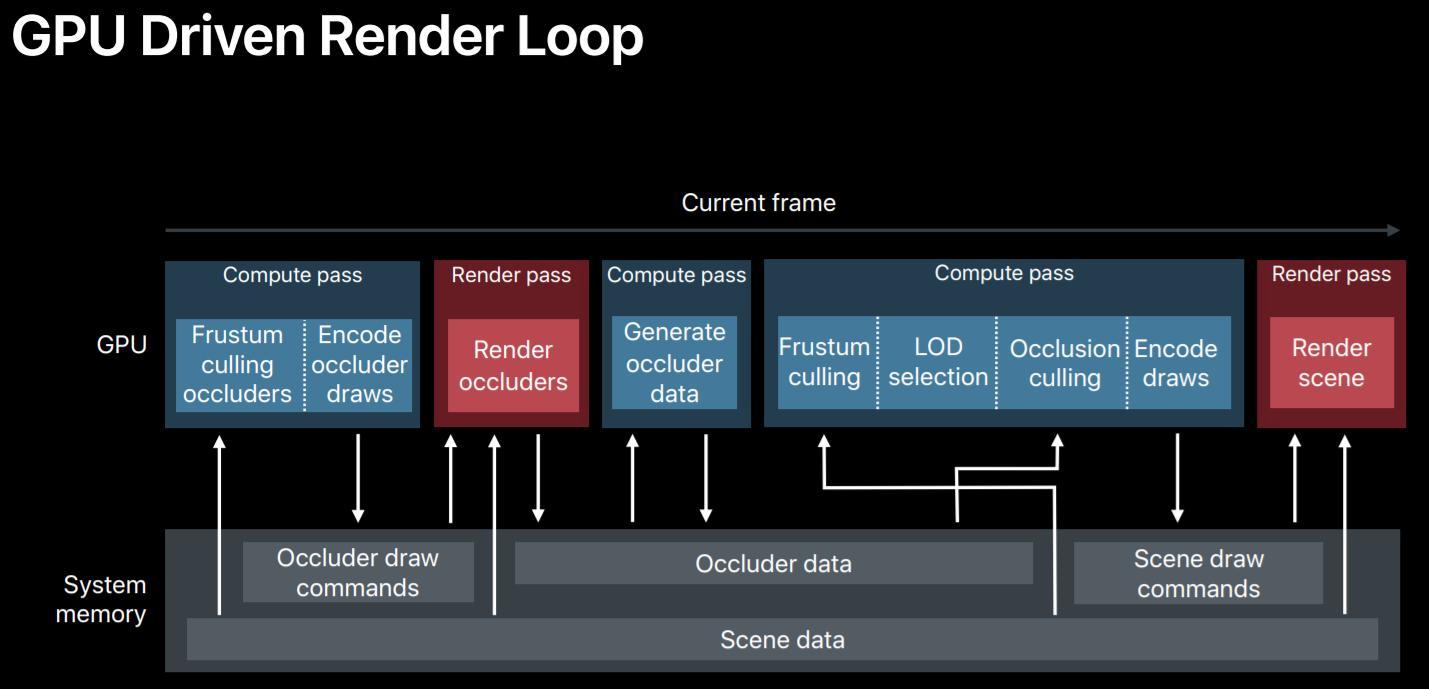
GPU Driven Render Pipeline
将场景完整load到显存中,完全由GPU处理:DrawPrimitive -> DrawScene
@《刺客信条:大革命》
Mesh Cluster Rendering
- 将Mesh分成同样三角形数量的Cluster,便于交给GPU做裁剪等计算
- 不可见的Cluster不渲染;Culling流程:
- 尽可能裁剪掉不可见的三角形
- 将可见的三角形组成同一个Buffer
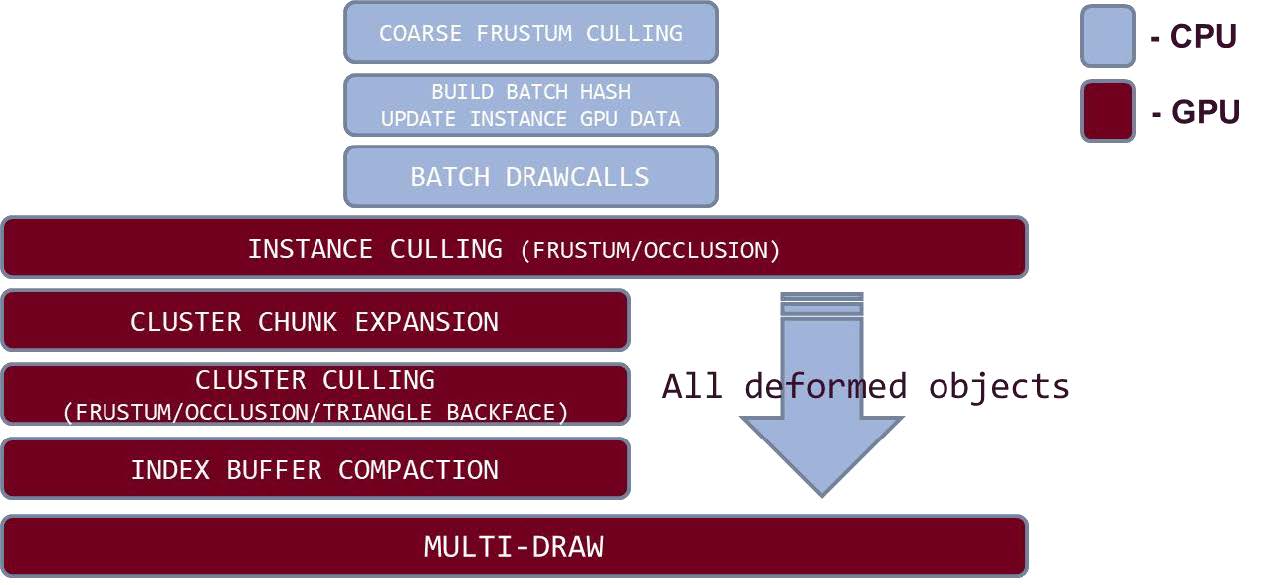
GPU Driven Pipeline
- CPU端:
- 根据材质不同组合Instance
- 根据相机距离LoD
- 打包交给GPU做后续处理
- GPU Instance Culling
- Instance Culling
- 将(64个)Cluster组成一个Chunk,再次Culling,以加速
- GPU Cluster Culling
- Chunk -> Cluster -> Triangle 一步步裁剪,将视锥外、背面的全部裁剪
- Index Buffer Compaction 将可见三角形的依次写入备用Index Buffer
- 三角形顶点顺序不统一时,可能导致前后帧三角形顶点顺序不一致,由于Z-Buffer精度有限,导致Z-Fighting问题 => 硬件Multi-Indirect Draw Call或可解决此问题
- 对高精度的Mesh效率非常高
- Codec Triangle Visibility in Cube : Backface Culling
- 每个Cluster存储每个三角形对两个方向的可见性
- 利用这一数据快速做Backface Culling
Occlusion Culling for Camera and Shadow
- 利用前一帧Z-Buffer的方法:
- 取当前帧的一部分(如300个)近处大Mesh作为可能的Occluder渲染Z-Buffer
- 将上一帧的深度重投影到当前帧,用于补充当前帧Z-Buffer空缺处
- 保守估计Culling Instance -> Chunk -> Cluster -> Triangle
- 问题:高速移动物体存在一定Artifact
- Two-Phase Occlusion Culling
- 快速绘制通过上一帧的Z-Buffer Test的Instance的当前帧Z-Buffer
- 再利用当前帧不完整的Z-Buffer,测试剩余所有Instance,选出可见者
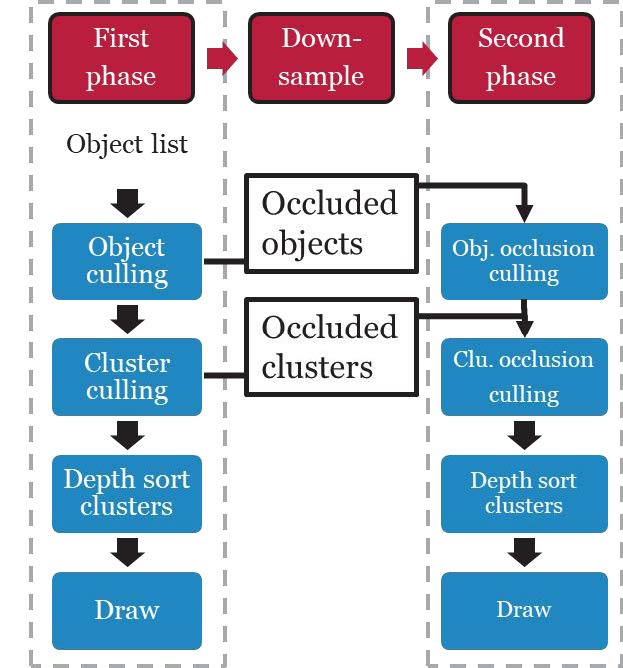
- 更加准确
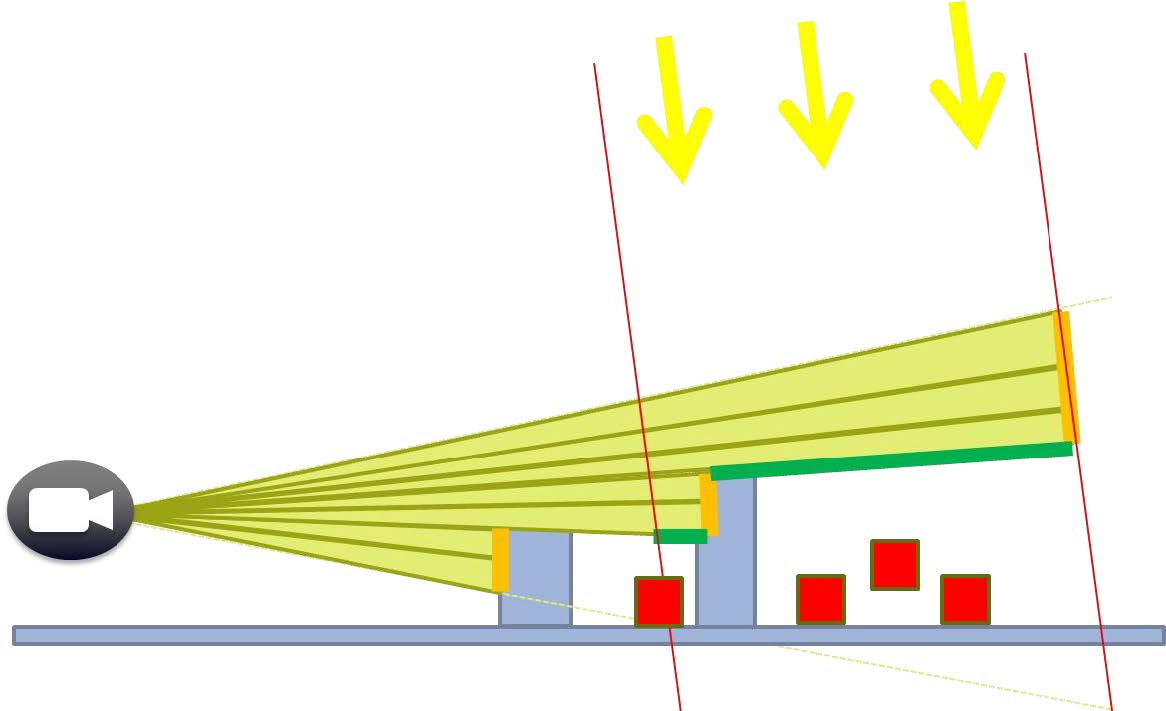
- Fast Occlusion for Shadow
- Shadow中生成深度时对几何细节量敏感
- 对每个Cascade,将上一帧相机深度重投影至当前帧Shadow深度,并混合上一帧Shadow深度
- 只有摄影机可见区域内需要生成阴影:只对相机可见的Instance生成Shadow的Z-Buffer
Visibility Buffer
- Forward Rendering:所有互相遮挡、透明的物体需要做重复计算
- Deferred
Shading:用G-Buffer存储可见Pixel的各种数据,只对G-Buffer做光照计算
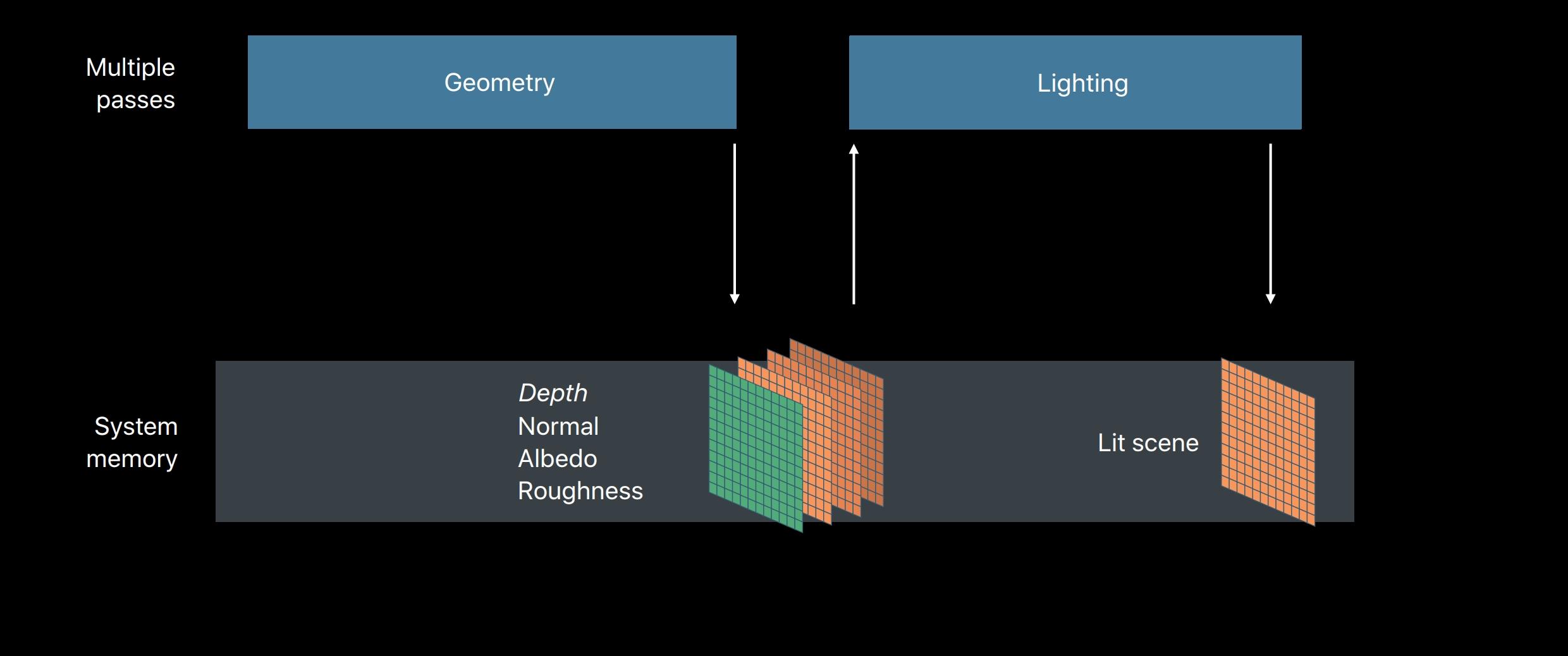
- G-Buffer的存储、IO开销大
- 复杂场景下,因为难以判断可见性,在生成G-Buffer时产生Over draw,多次绘制同一像素时开销大
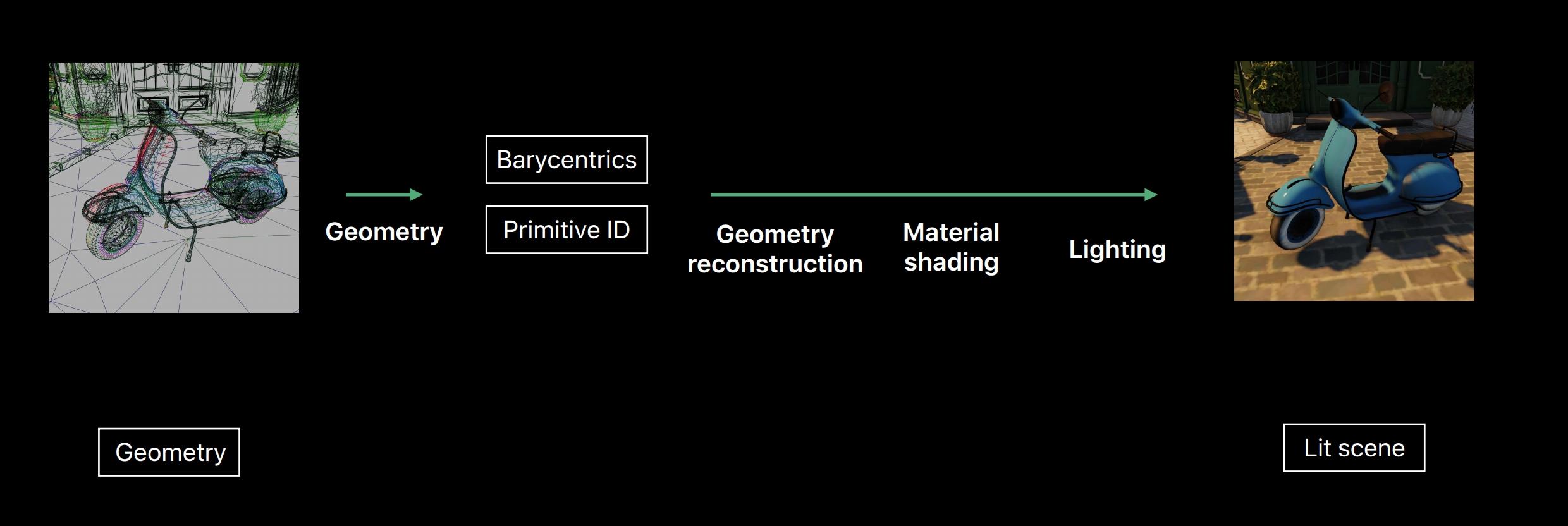
- Visibility Buffer:
- 第一遍渲染时,只在Buffer中存储: (Alpha masked bit, DrawID, PrimitiveID, MaterialID, …)
- 根据各种ID读取对应贴图,再做重心坐标插值着色
- 几乎没有Over Draw
- Cache Miss率低
- Pipeline
- Visibility Buffer + Deferred Shading
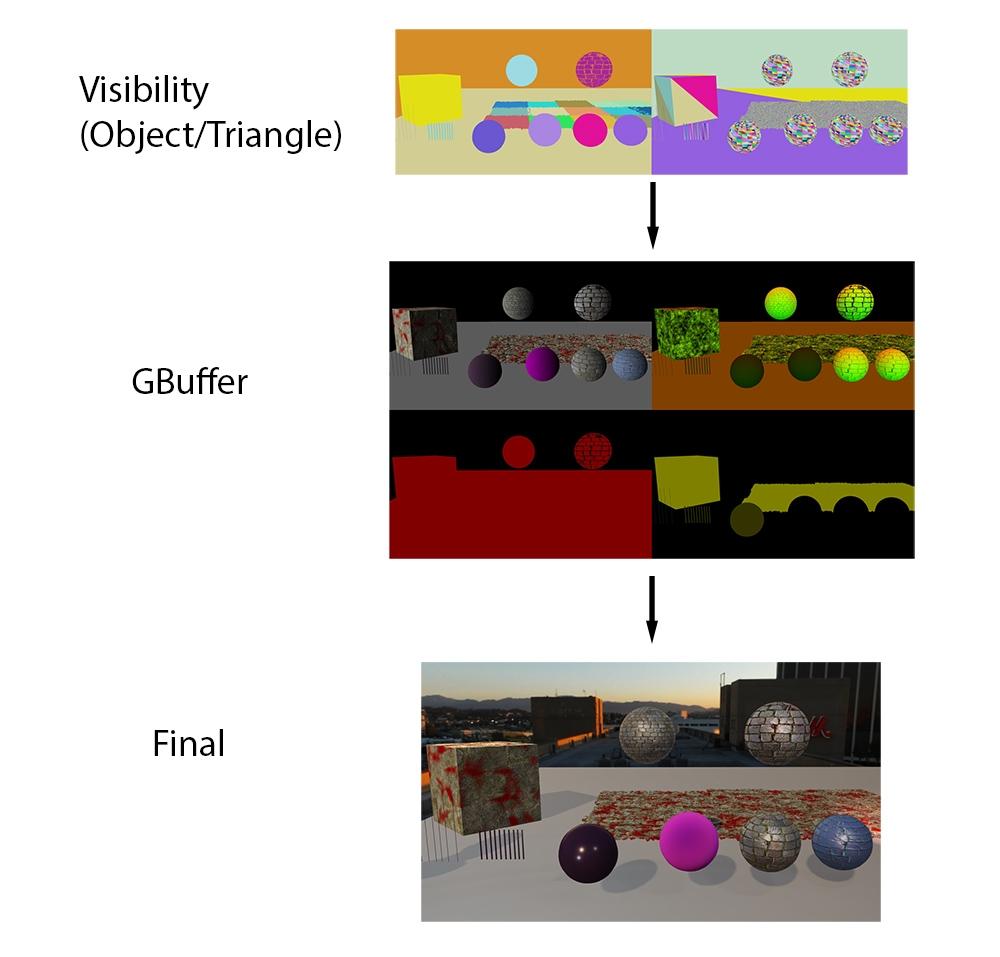
- 一般来说,草丛等复杂细节情况可直接用Visibility Buffer渲染,主角等主要内容Gather到G-Buffer再渲染
- 注意点:MIPMAP采样时的插值平滑问题
Virtual Geometry - Nanite
Overview
Virtual Texture
- Idea:将场景中所有贴图加载到内存中开销非常大,能否只加载可见部分且LoD后精度的贴图
- 所有材质加载到同一张“大贴图”中,并对整个贴图做MIPMAP
- 预烘焙这张“大贴图”,并做MIPMAP
- 根据View区域动态加载所需的部分
Idea of Nanite
- Virtual Geometry like Virtual Texture
- 挑战:几何数据是非Uniform的、互相之间可能没有关联性、Mesh数据难以Filter(SDF、Voxel、Point Cloud可以Filter)
- Voxel ?
- 数据量非常大
- 属性Leaking
- 非常不适合目前的美术工作流
- Subdivision Surface ?
- 需要使用四边形面
- Subdivision很难做Downsampling
- Maps-based Method ? 高度图、置换等
- 很难做非常细的几何细节
- NVIDIA正在从硬件上做这方面的更多工作,或许还有发展的可能
- Point Cloud ?
- 效果不好
- Over Draw
- 材质如何绑定
- Triangle !
- 绘制三角形数量恰多于屏幕像素数量 1 more triangle per pixel
Geometry Representation
Cluster-based LoD
- Clusters, 128 Triangles per cluster

- View Dependent LoD
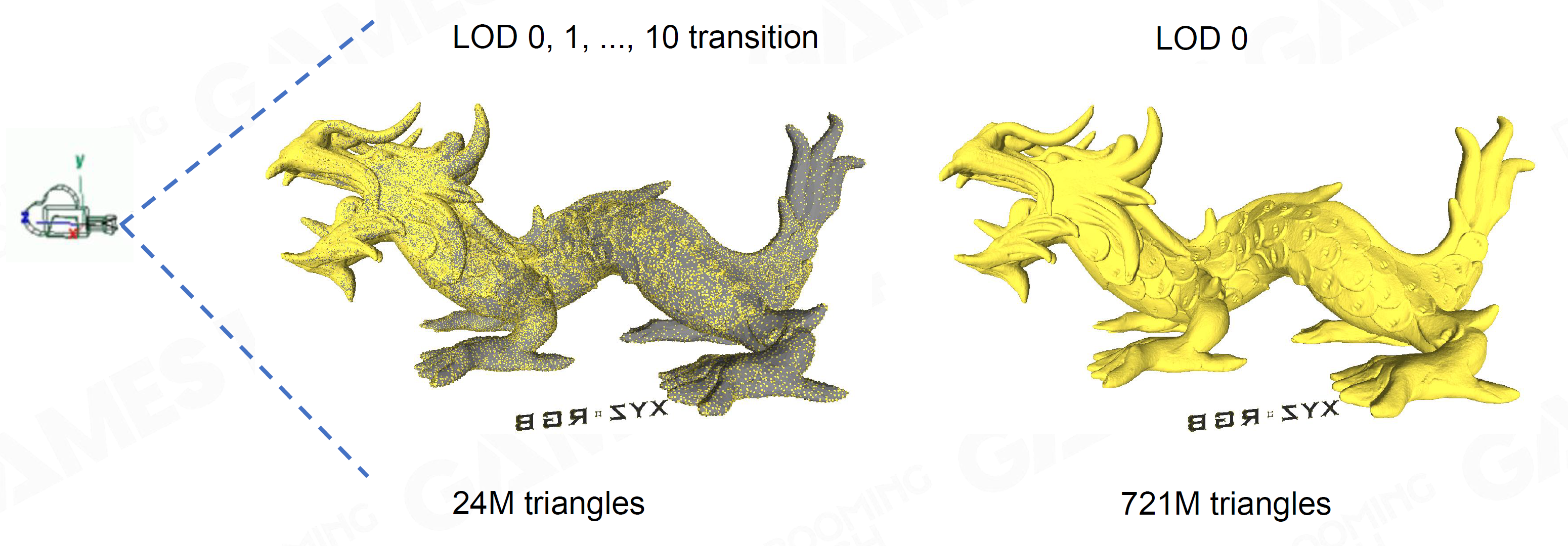 用远少于LoD0的Triangle数实现1 more triangle per pixel的精度
用远少于LoD0的Triangle数实现1 more triangle per pixel的精度 - Naive Solution
- Cluster两两合并,减少一半三角形,得到简单的Cluster Hierarchy
- 根据View得到对Cluster的Cut Line,选择对应精度的Cluster
- Like Virtual Texturing,流式加载数据
- 问题:不同Cluster之间的Juction问题
- 锁住Cluster的边:边缘处的Triangle密度过高
- 面片简化利用率不高
- 密度不均匀,产生画面Artifact(缝合线感)
- 锁住Cluster的边:边缘处的Triangle密度过高
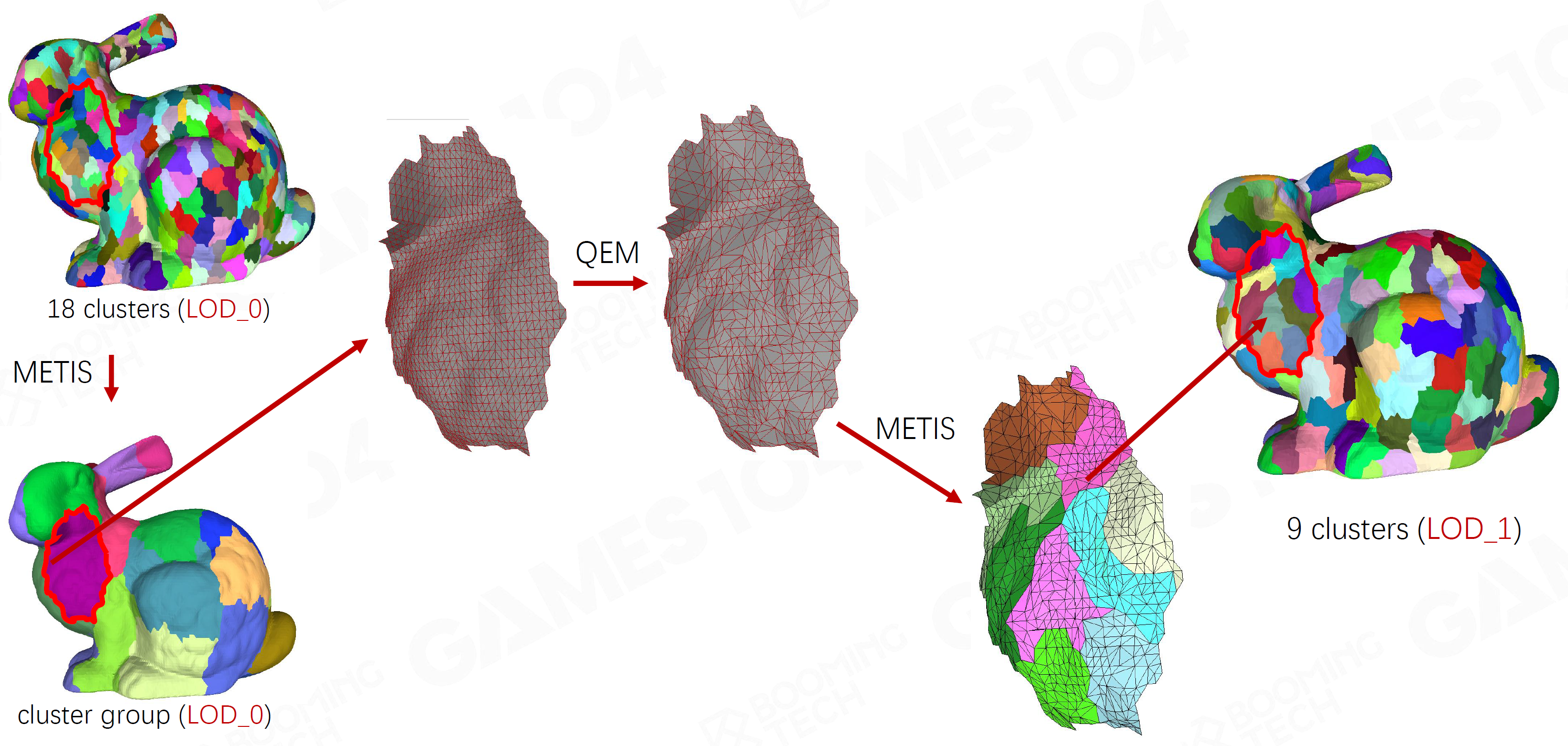
- Nanite Solution
- Cluster Group
- 将一定数量的Cluster组成一个Group
- 每个Group选择同样的LoD级别
- 在Group内做简化,锁住Group的边
- 简化后重新生成Cluster
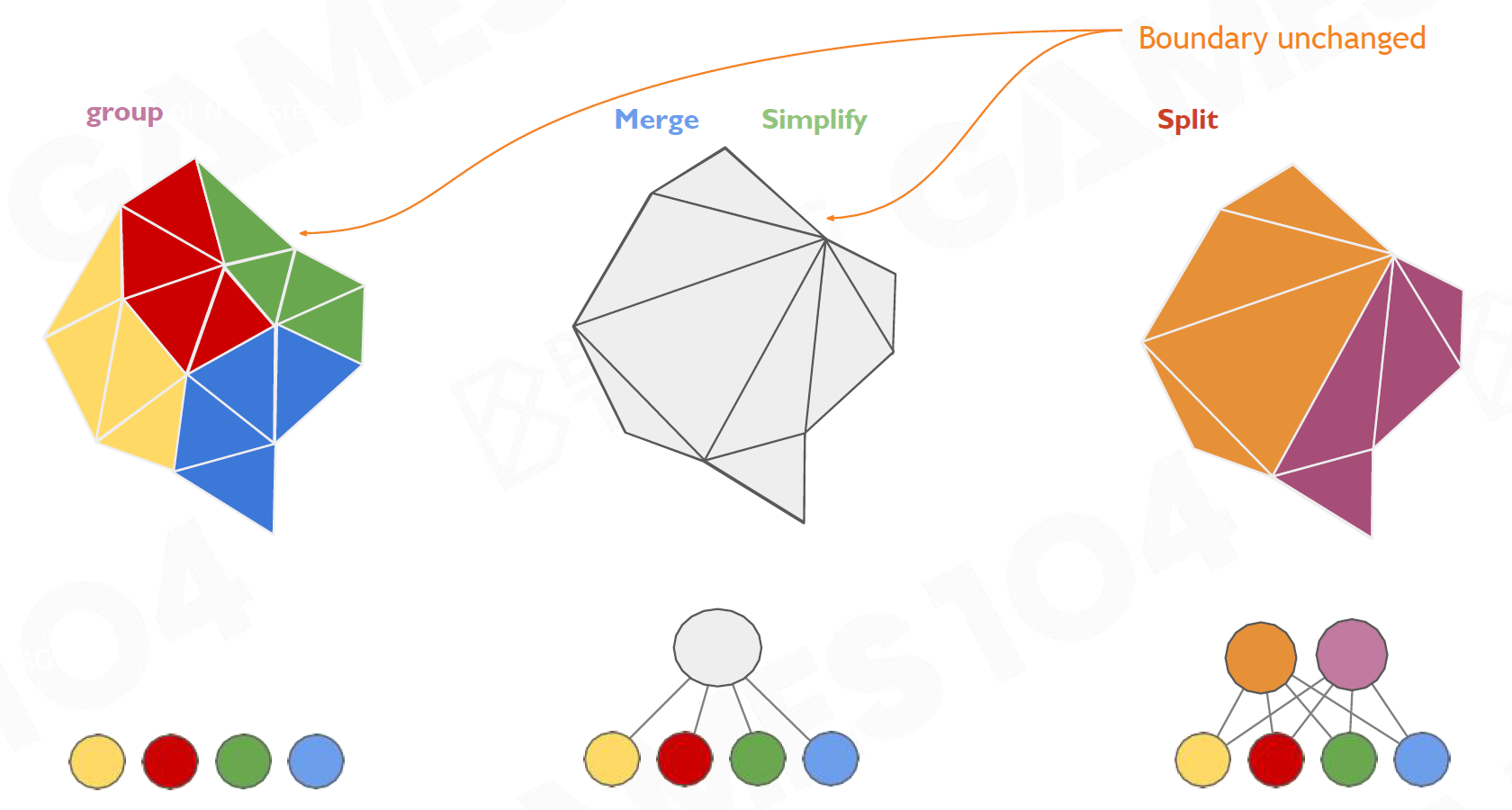
- 每一级LoD,选择不同的Group边锁住
 类似图片降采样时的Jiltering
类似图片降采样时的Jiltering - 构建DAG(有向无环图)
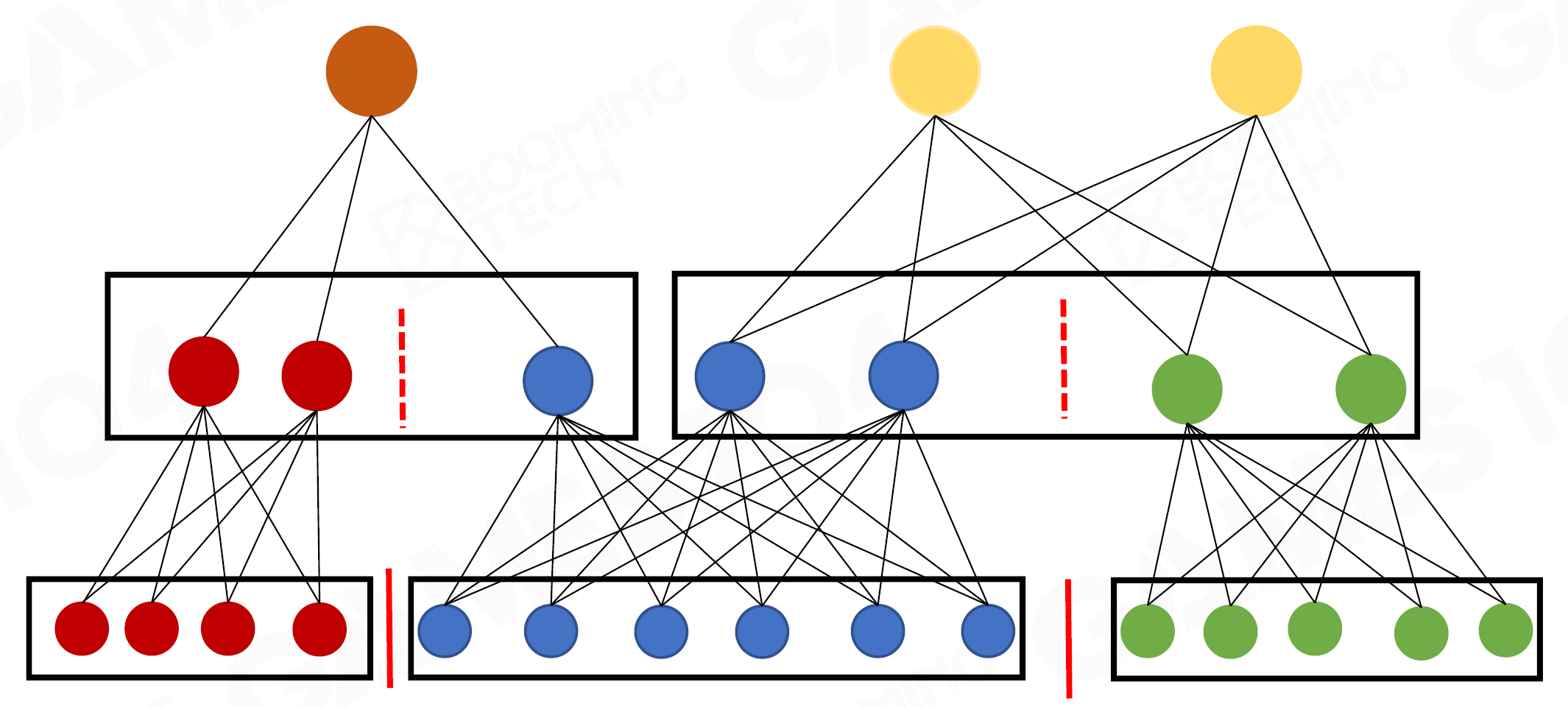
- 细节:QEM,保证Error计算的精确性,且Error单向向上传递
 ##### Runtime LoD
##### Runtime LoD
- Cluster Group
- 直接在DAG中选择?但直接在DAG中遍历非常复杂
- 同属于一个Group的Cluster用同样的LoD等级
- 并行地做View Dependent Cut
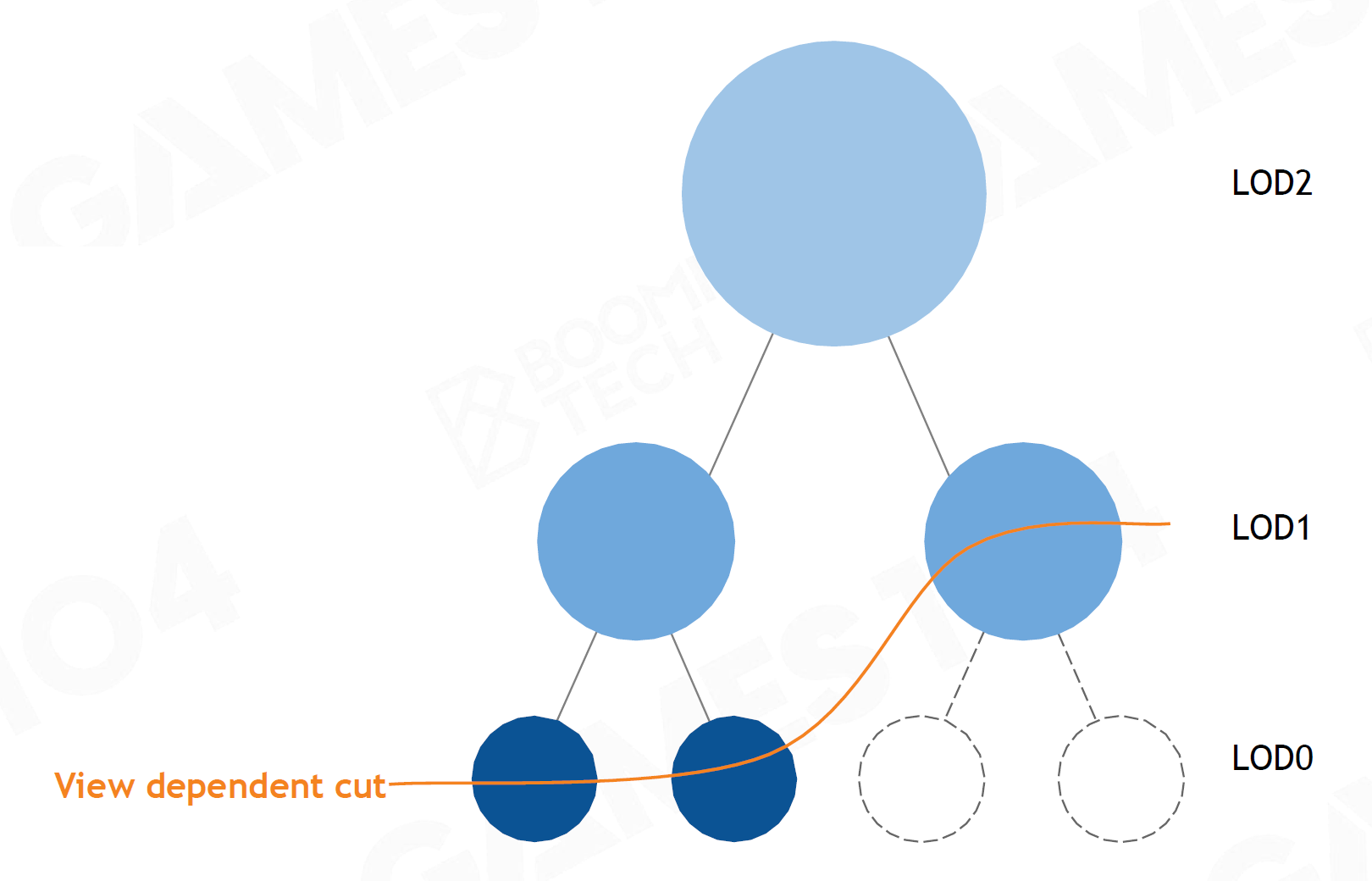
- 规则:
- Parent View Error >= Child View Error
- LoD Cull 判定条件
- Render : ParentErr > threshold && ClusterErr <= threshold
- Cull : ParentErr <= threshold || Cluster > threshold
- 若Parent已经足够精确,则无需再Check Child
- ParentErr <= threshold
- 规则:
- 每一个Cluster Group的每一次LoD Selection是独立的,不会上一级没通过再看下一级
BVH Acceleration for LoD Selection
- 想法核心:把LoD0、LoD1、…每一层LoD独立组成一个BVH,最后再将所有BVH组成一个大的树
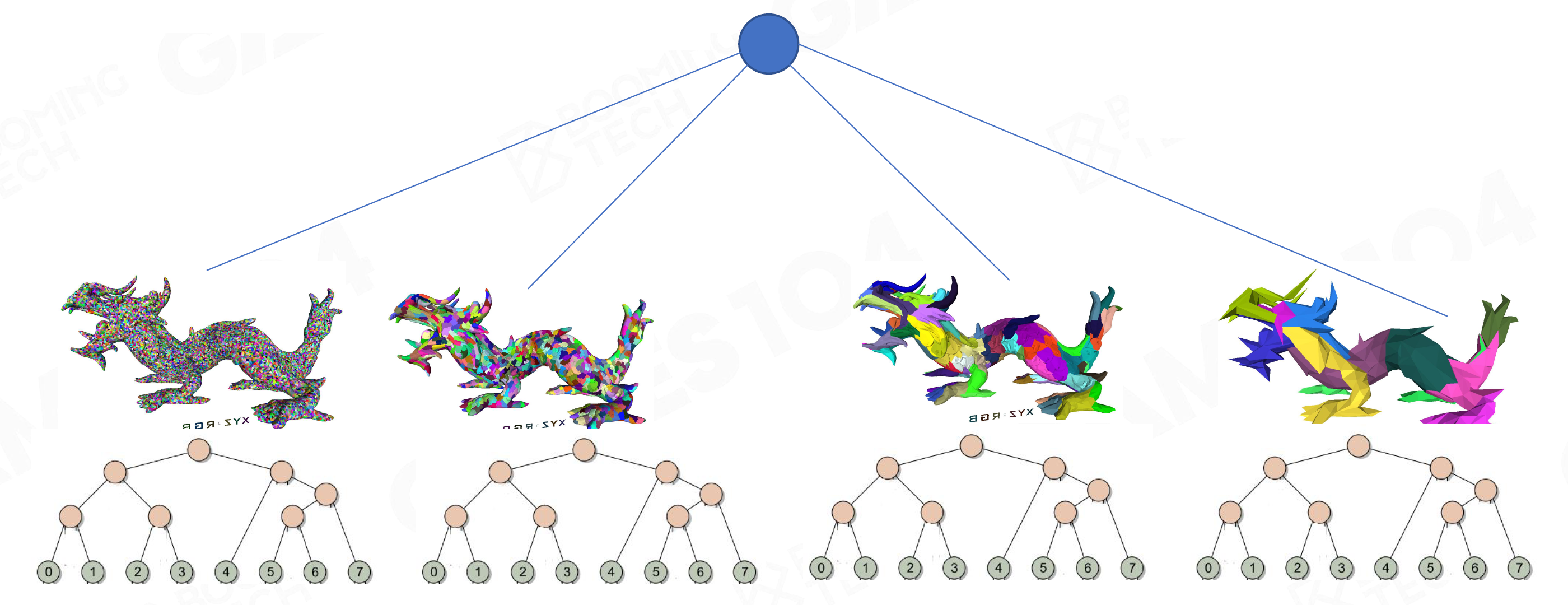
- 方便地取BVH的Bounding,做相机剔除后再Check,节省了非常多计算量
Hierarchical Culling
加速的Trick
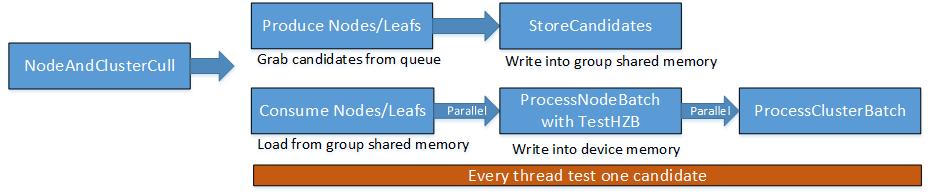
Rendering
Software and Hardware Rasterization
- 硬件光栅化:光栅化单元是2*2的Quad(为了算ddx和ddy),用4*4的Tile遍历加速,剔除不参与渲染的Tile
- Triangle小到1个pixel的大小时 —— 上述优化均失效
- 软件光栅化:
- Compute Shader直接接管小三角形的光栅化
- 若三角形小于1pixel,则直接给pixel着色
- 直接通过三角形的UV算ddx、ddy,不用Tile计算
- 若三角形边长小于18pixel,则使用软件光栅化(Scanline),反之回到硬件光栅化
- 深度测试:存储64bit的atomic数据 —— 32bit Depth + 25bit Visible Cluster Index + 7bit Triangle Index (Visibility Buffer)
- 硬件光栅化
- Imposter:对足够远、足够小的Instance,生成12*12个方向的的12*12大小的各种贴图(Aldobe、Normal、…)
- Overdraw:
- 没有逐像素剔除
- 没有硬件HiZ像素剔除
- 软件HZB来自上一帧
- 大Cluster、重叠Cluser、聚合、快速移动等带来的Overdraw
- …
- 期待硬件支持更完善,不要用软件Trick完成这些ideas
Deferred Materials
- 早期:
- 将每个Material ID转换为一个Depth值,记录为一张Depth Buffer
- 扫描整张Buffer,判断Depth与Material ID相等时,用对应Material绘制
- 消耗较大
- Tiled Based的思想
- 将全屏幕分为多个Tile,标记每个材质是否在Tile中出现
- 在逐材质扫描整张Buffer时,可以直接跳过没有该材质的Tile
Shadow
- Shadow Casting的精度要求很高
- Ray Trace? Nanite几何表达无法兼容
- Cascaded Shadow Map 具体略 本质:View-dependent Sampling
- Sample Distribution Shadow Maps 相当于将Cascaded Shadow Maps中重复的、视锥外的像素去除的Shadow Maps
- Shadow Map的本质:根据相机视空间的精度,采样光空间
Virtual Shadow Map - A Cached Shadow System
- 核心思想:将Shadow Map切成足够小的块,确保每一小块与视空间的采样率高度一直,且只更新产生光照变化的块
- 实际:给每个光源一张16k的VSM(点光源为6个方向的6张),仅可见像素会被Cache
- 相机运动、光照几何变化时,更新部分Tile即可
Streaming and Compression
Streaming
- 流送的核心:只Load需要的数据到内存中
- 构建成逐个Page,动态加载
Compression
- 内存数据:Quantization
- 浮点变定点等
- 硬盘数据
- LZ Compression
- 显存加载自动解压缩